To be or NAT to be? Multus CNI for Telco Workloads on Kubernetes
The Constraint
SIP and RTP care about address ownership.
With SIP, the address in the packet is not enough. The application also writes addresses into SIP headers and SDP. RTP then uses those addresses for media. If the application advertises one IP:port tuple and the peer sees packets arriving from another one, the call may still signal successfully while media goes nowhere.
That was the constraint I had to design around: a Kubernetes pod needed a stable public identity, and the UDP source port had to remain the port the application advertised.
The examples below are sanitized. Names are generic, addresses are placeholders, and the code is intentionally written as pseudocode rather than something to copy into production.
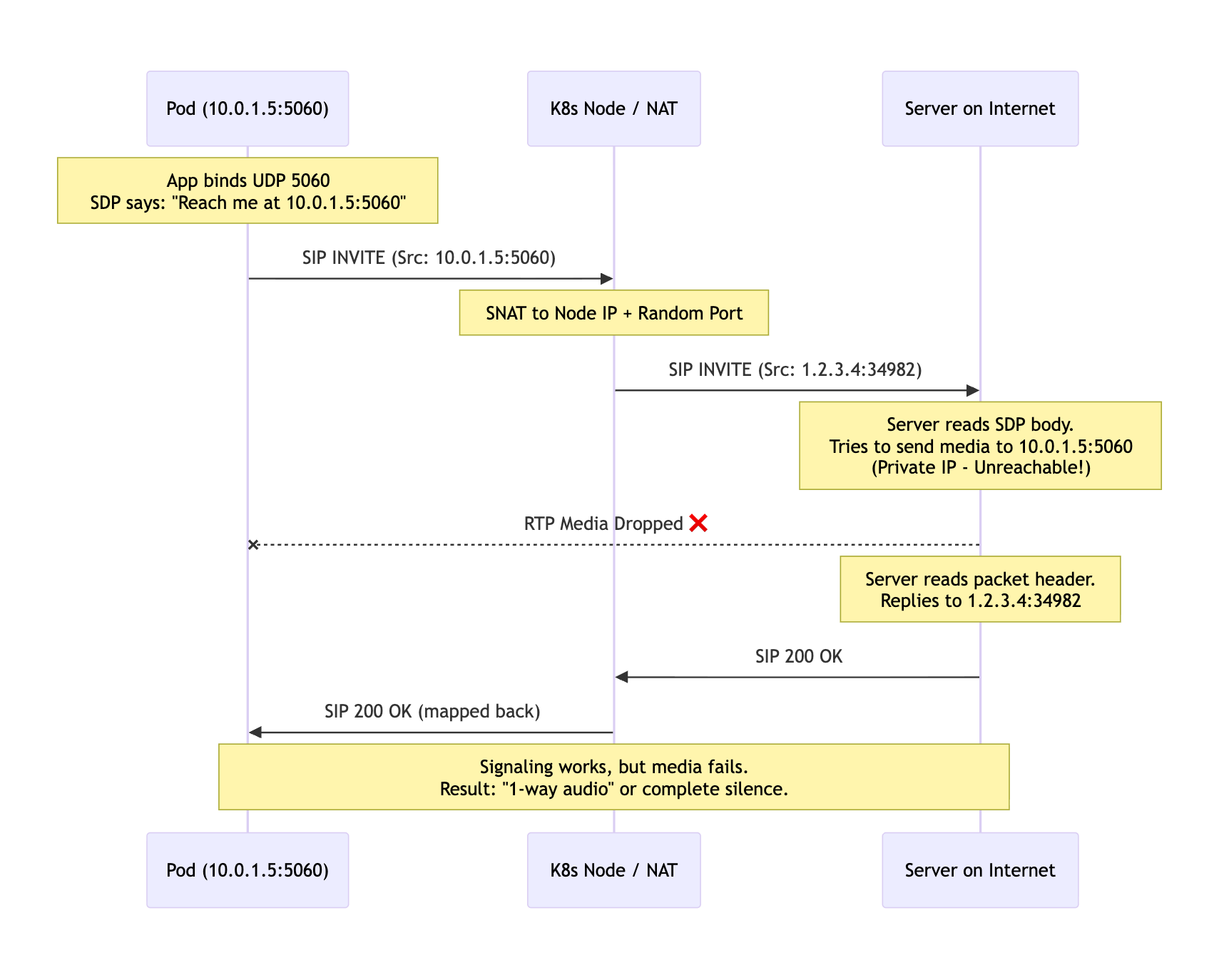
The Packet That Broke the Assumption
The first failure was not subtle. A pod sent SIP from a private address, Kubernetes or the VPC rewrote the packet on the way out, and the remote side tried to send media to the address found in SDP.
Signaling could still limp along because replies followed the NAT mapping. RTP did not have that luxury.
mermaid
sequenceDiagram
participant P as Pod (10.0.1.5:5060)
participant N as K8s Node / NAT
participant I as Server on Internet
Note over P: App binds UDP 5060<br/>SDP says: "Reach me at 10.0.1.5:5060"
P->>N: SIP INVITE (Src: 10.0.1.5:5060)
Note over N: SNAT to Node IP + Random Port
N->>I: SIP INVITE (Src: 1.2.3.4:34982)
Note over I: Server reads SDP body.<br/>Tries to send media to 10.0.1.5:5060<br/>(Private IP - Unreachable!)
I--xP: RTP Media Dropped ❌
Note over I: Server reads packet header.<br/>Replies to 1.2.3.4:34982
I->>N: SIP 200 OK
N->>P: SIP 200 OK (mapped back)
Note over P,I: Signaling works, but media fails.<br/>Result: "1-way audio" or complete silence.
The important part is not SIP syntax. The important part is that a middlebox changed the network tuple after the application had already told the peer what tuple to use.
Once that happens, there are only three broad options:
- Make the application aware of the translated address.
- Relay the media through something that owns a reachable address.
- Stop translating the media path.
For this workload, I wanted option 3.
Why NAT Keeps Showing Up
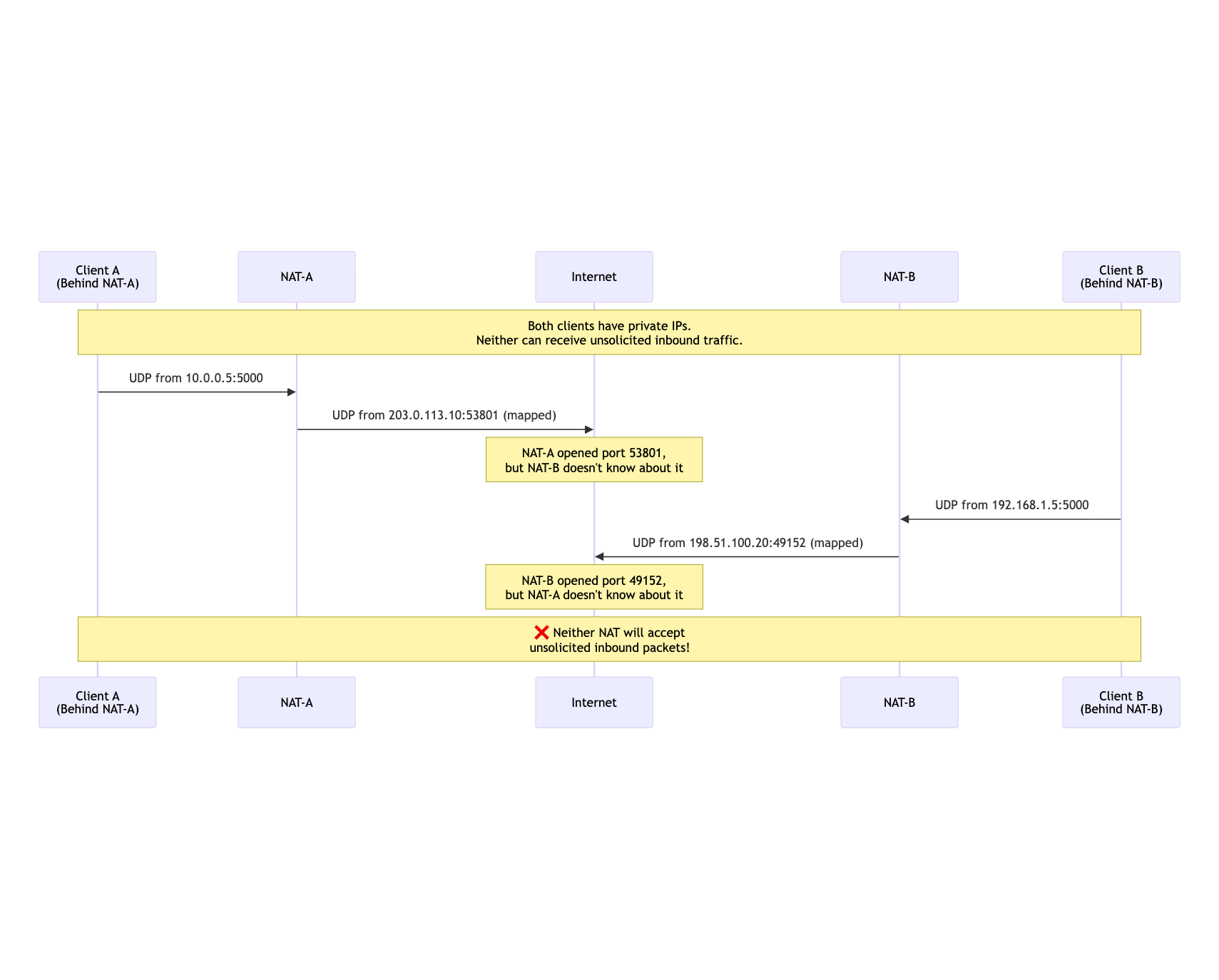
UDP does not establish a connection in the way TCP does. A NAT device can create a temporary mapping after an outbound packet, but that mapping is usually scoped to the peer that was contacted. With restrictive or symmetric NAT, the translated port may change per destination.
When both sides are behind NAT, direct communication needs help.
mermaid
sequenceDiagram
participant ClientA as Client A<br/>(Behind NAT-A)
participant NAT_A as NAT-A
participant Internet as Internet
participant NAT_B as NAT-B
participant ClientB as Client B<br/>(Behind NAT-B)
Note over ClientA,ClientB: Both clients have private IPs.<br/>Neither can receive unsolicited inbound traffic.
ClientA->>NAT_A: UDP from 10.0.0.5:5000
NAT_A->>Internet: UDP from 203.0.113.10:53801 (mapped)
Note over Internet: NAT-A opened port 53801,<br/>but NAT-B doesn't know about it
ClientB->>NAT_B: UDP from 192.168.1.5:5000
NAT_B->>Internet: UDP from 198.51.100.20:49152 (mapped)
Note over Internet: NAT-B opened port 49152,<br/>but NAT-A doesn't know about it
Note over ClientA,ClientB: ❌ Neither NAT will accept<br/>unsolicited inbound packets!
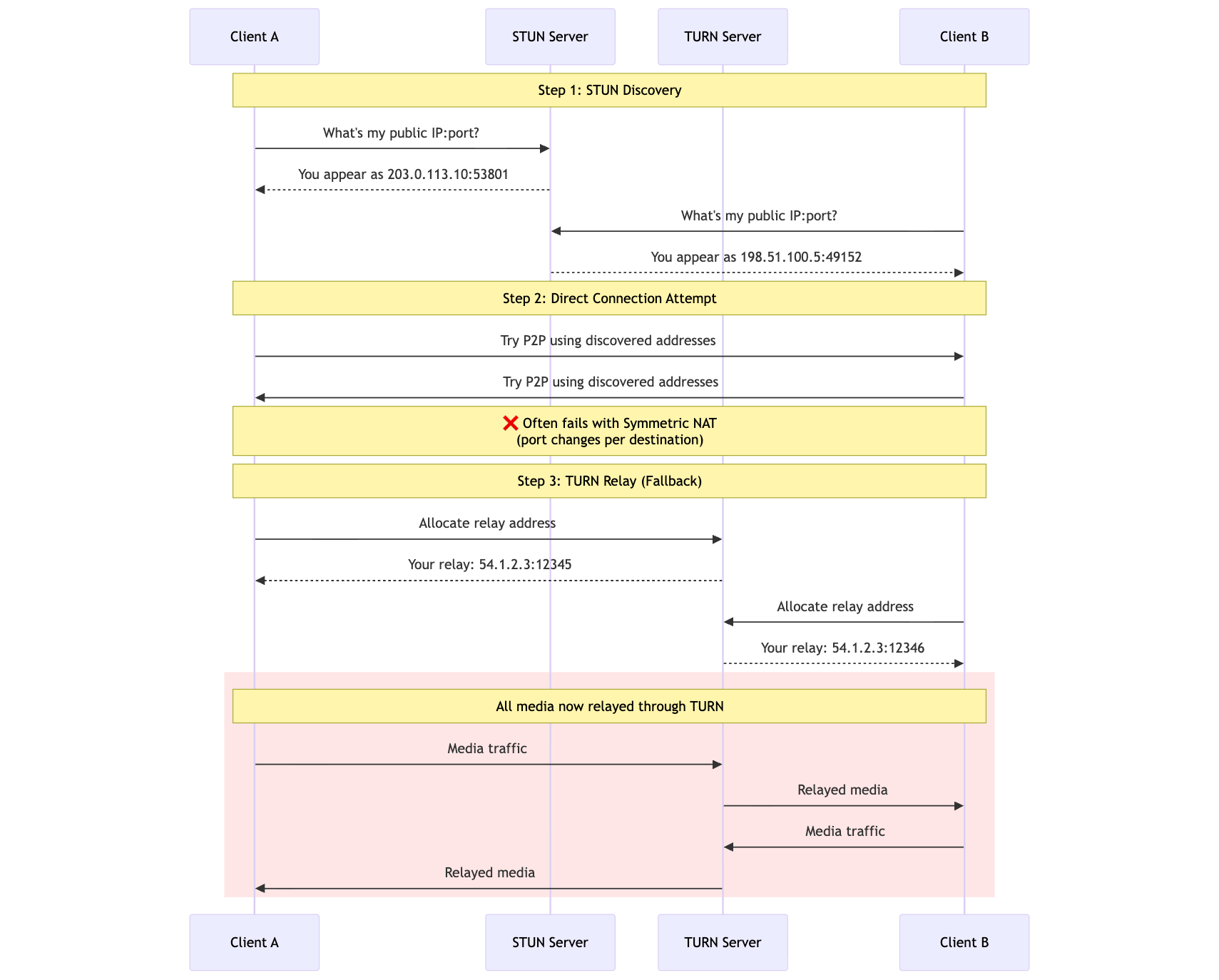
WebRTC deals with this using ICE. STUN tells a client what address it appears to have from outside. TURN gives up on direct media and relays it.
mermaid
sequenceDiagram
participant CA as Client A
participant STUN as STUN Server
participant TURN as TURN Server
participant CB as Client B
Note over CA,CB: Step 1: STUN Discovery
CA->>STUN: What's my public IP:port?
STUN-->>CA: You appear as 203.0.113.10:53801
CB->>STUN: What's my public IP:port?
STUN-->>CB: You appear as 198.51.100.5:49152
Note over CA,CB: Step 2: Direct Connection Attempt
CA->>CB: Try P2P using discovered addresses
CB->>CA: Try P2P using discovered addresses
Note over CA,CB: ❌ Often fails with Symmetric NAT<br/>(port changes per destination)
Note over CA,CB: Step 3: TURN Relay (Fallback)
CA->>TURN: Allocate relay address
TURN-->>CA: Your relay: 54.1.2.3:12345
CB->>TURN: Allocate relay address
TURN-->>CB: Your relay: 54.1.2.3:12346
rect rgb(255, 230, 230)
Note over CA,CB: All media now relayed through TURN
CA->>TURN: Media traffic
TURN->>CB: Relayed media
CB->>TURN: Media traffic
TURN->>CA: Relayed media
end
TURN is the correct fallback for many browser-to-browser cases, but it is not free. It adds relay latency, consumes relay bandwidth, and moves media capacity into a shared service.
Core SIP does not solve NAT by itself. There are SIP-related NAT traversal tools, including symmetric response routing with rport (RFC 3581), SIP Outbound (RFC 5626), and ICE usage in SDP/SIP flows (RFC 8839, RFC 8840). Session Border Controllers can also hide a lot of complexity, but that still means adding a media-aware intermediary. For a server-side SIP/RTP workload that should own its media path, I needed the pod to own the reachable address.
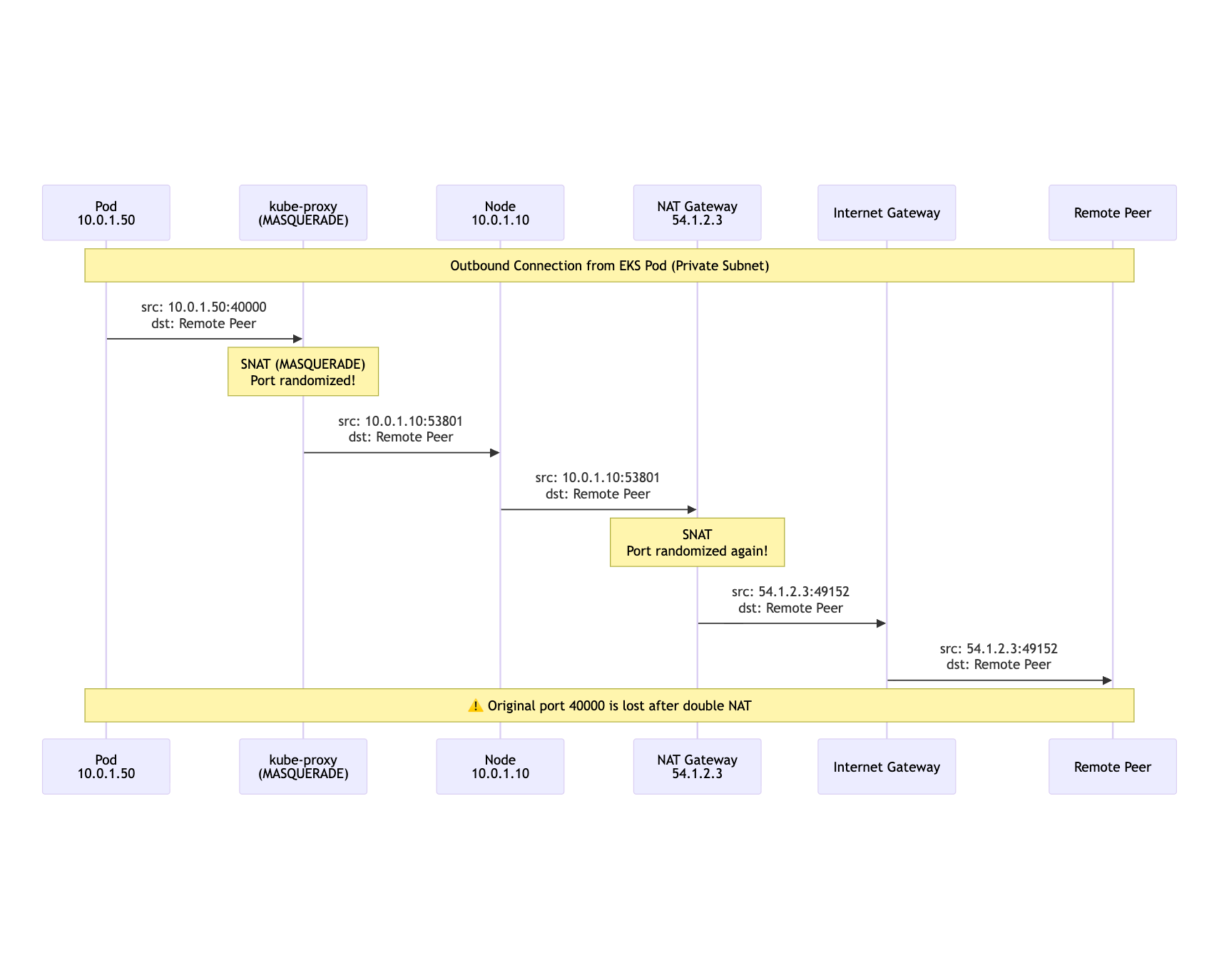
EKS Added More Translation
The default EKS shape made the problem worse. A pod in a private subnet could cross kube-proxy rules, the node stack, and a NAT Gateway before the packet reached the Internet.
mermaid
sequenceDiagram
participant Pod as Pod<br/>10.0.1.50
participant KP as kube-proxy<br/>(MASQUERADE)
participant Node as Node<br/>10.0.1.10
participant NAT as NAT Gateway<br/>54.1.2.3
participant IGW as Internet Gateway
participant Peer as Remote Peer
Note over Pod,Peer: Outbound Connection from EKS Pod (Private Subnet)
Pod->>KP: src: 10.0.1.50:40000<br/>dst: Remote Peer
Note over KP: SNAT (MASQUERADE)<br/>Port randomized!
KP->>Node: src: 10.0.1.10:53801<br/>dst: Remote Peer
Node->>NAT: src: 10.0.1.10:53801<br/>dst: Remote Peer
Note over NAT: SNAT<br/>Port randomized again!
NAT->>IGW: src: 54.1.2.3:49152<br/>dst: Remote Peer
IGW->>Peer: src: 54.1.2.3:49152<br/>dst: Remote Peer
Note over Pod,Peer: ⚠️ Original port 40000 is lost after double NAT
That flow is fine for traffic where only the remote service needs to be reachable. It is bad for a media server that has already advertised 203.0.113.50:40000 and expects the peer to send RTP there.
Bare EC2 instances in public subnets avoid most of this. That is why telecom stacks often end up there. The tradeoff is operational: slower rollout, less bin-packing, more custom lifecycle work, and less of the Kubernetes machinery that teams already use.
So the question became narrower: can a pod keep Kubernetes for lifecycle, but bypass Kubernetes for the media address?
Wrong Assumption 1: Public Nodes and hostNetwork
The first idea was to put a node group in public subnets and run the workload with hostNetwork: true.
The assumption was simple:
- The pod binds UDP
40000. - The node has a public IP.
- The peer sends packets to
<node-public-ip>:40000.
The measurement said otherwise.
# Test pod using the host network namespace
kubectl run udp-test --image=alpine --restart=Never \
--overrides='{"spec":{"hostNetwork":true}}' \
-- sh -c "apk add socat && socat -v UDP-LISTEN:40000,fork EXEC:'/bin/cat'"
# Look at conntrack state
sudo conntrack -L -p udp | grep 40000
# Look for source NAT rules
sudo iptables-save | grep -E 'MASQUERADE|random-fully'
The useful observation was the --random-fully MASQUERADE behavior in the path. Even when the packet originated from the host network namespace, the source port could still be rewritten by rules installed for Kubernetes service traffic and hairpin behavior.
hostNetwork also had a design problem independent of that measurement:
| Problem | Why it mattered |
|---|---|
| Port collisions | Multiple pods cannot all bind 5060 on the same node |
| Shared identity | The node IP is not a per-pod identity |
| Scheduling coupling | Placement decides external identity |
| Security boundary | The pod shares the host network namespace |
The correction was to stop trying to make the node IP behave like a pod IP.
Wrong Assumption 2: Put an NLB in Front
The second idea was a Network Load Balancer with UDP listeners.
That solved reachability. It did not solve identity.
The main issue was not simply that UDP stickiness can be awkward. The real problem was that the application still did not own the address it needed to advertise.
NLBs do support UDP listeners. The difference is what the protocol gives the load balancer to work with. For TCP, a connection has a clear lifetime, and the load balancer can keep that connection associated with one target. For UDP, there is no connection, but it is still not round-robin per packet: the NLB hashes the flow tuple: protocol, source IP, source port, destination IP, and destination port (AWS docs).
Packets with the same UDP tuple should keep landing on the same target while that flow is active. If the client changes source port, the packet reaches a different NLB IP, or the UDP flow sits idle past the NLB timeout, the next packet is a new flow and can be hashed to a different target. AWS documents the UDP flow idle timeout as 120 seconds and not configurable (AWS docs).
That can work for a simple UDP request/response service where each flow is self-contained. SIP/RTP is not that shape. SIP signaling may be one flow, while RTP media uses separate ports negotiated in SDP. Those media flows can hash independently from signaling.
There is also a practical listener problem: RTP usually needs a port range. An NLB listener is configured for a specific protocol and port, not "whatever UDP port this pod negotiated in SDP". You can create many listeners, but that turns the RTP range into load balancer configuration, and Network Load Balancers have finite listener quotas (AWS quotas). A media range of thousands of ports does not map cleanly to NLB listeners and target groups.
The workload still has to advertise an address and port that the peer can send media to directly. The NLB address is reachable, but it is not the pod's own identity, and it is not a good representation of the pod's RTP port range.
With an NLB:
- The peer sends traffic to the NLB address.
- The pod receives traffic through a load-balanced path.
- The pod still has to decide what IP to put into SIP headers and SDP.
- Replies must return through a path that keeps the peer seeing the advertised address.
If the pod replies directly, the peer sees a different source address. If the pod always replies through the NLB, the media path is no longer owned by the pod and the design becomes tightly coupled to load balancer behavior.
That can be fine when the load balancer is the service identity. For SIP/RTP, where the workload needs to advertise and source the same tuple, it is the wrong abstraction.
The Shape That Matched the Protocol
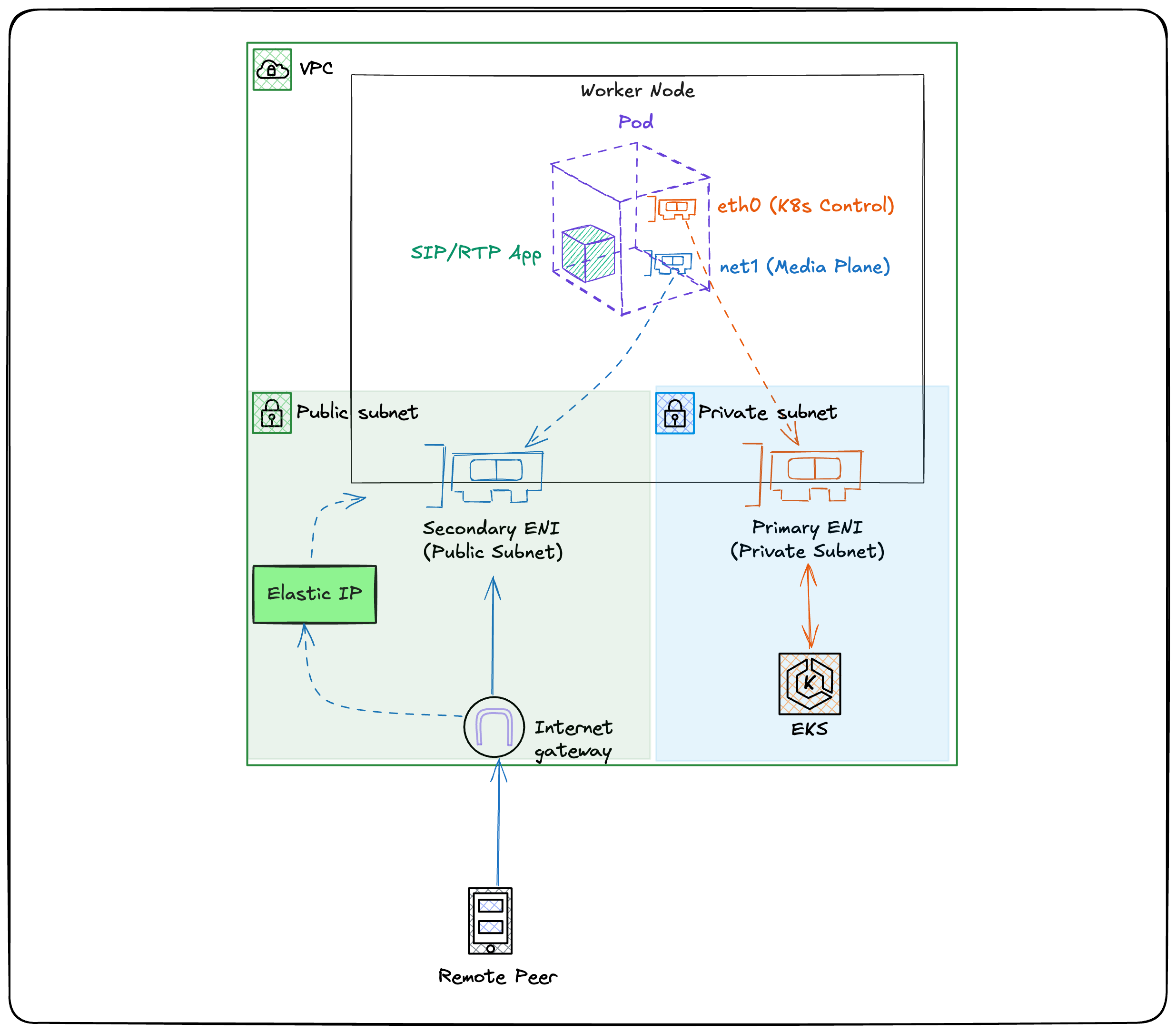
The design that held up was to treat the pod like a small VM for media traffic:
- Keep
eth0for normal Kubernetes traffic. - Add
net1with Multus for SIP/RTP. - Put
net1in the public-subnet path. - Associate an Elastic IP with the private IP used by
net1. - Force packets sourced from that identity to leave via
net1.
mermaid
flowchart LR
subgraph "VPC"
subgraph "Private Subnet"
Node[Worker Node<br/>Primary ENI]
end
subgraph "Public Subnet"
SecENI[Secondary ENI]
end
IGW[Internet Gateway]
RT[Route Table<br/>0.0.0.0/0 → IGW]
end
Node -- "eth0<br/>(K8s traffic)" --> PrivateRT[Private Route Table]
SecENI -- "net1<br/>(Telecom traffic)" --> RT
RT --> IGW
Pod[Pod] -- "eth0" --> Node
Pod -- "net1" --> SecENI
SecENI <--> EIP[Elastic IP]
EIP <--> IGW
IGW <--> Internet[Internet]
This keeps the control plane boring. Kubernetes API traffic, probes, logs, and metrics stay on eth0. Media traffic gets a separate interface, route table, and public identity.
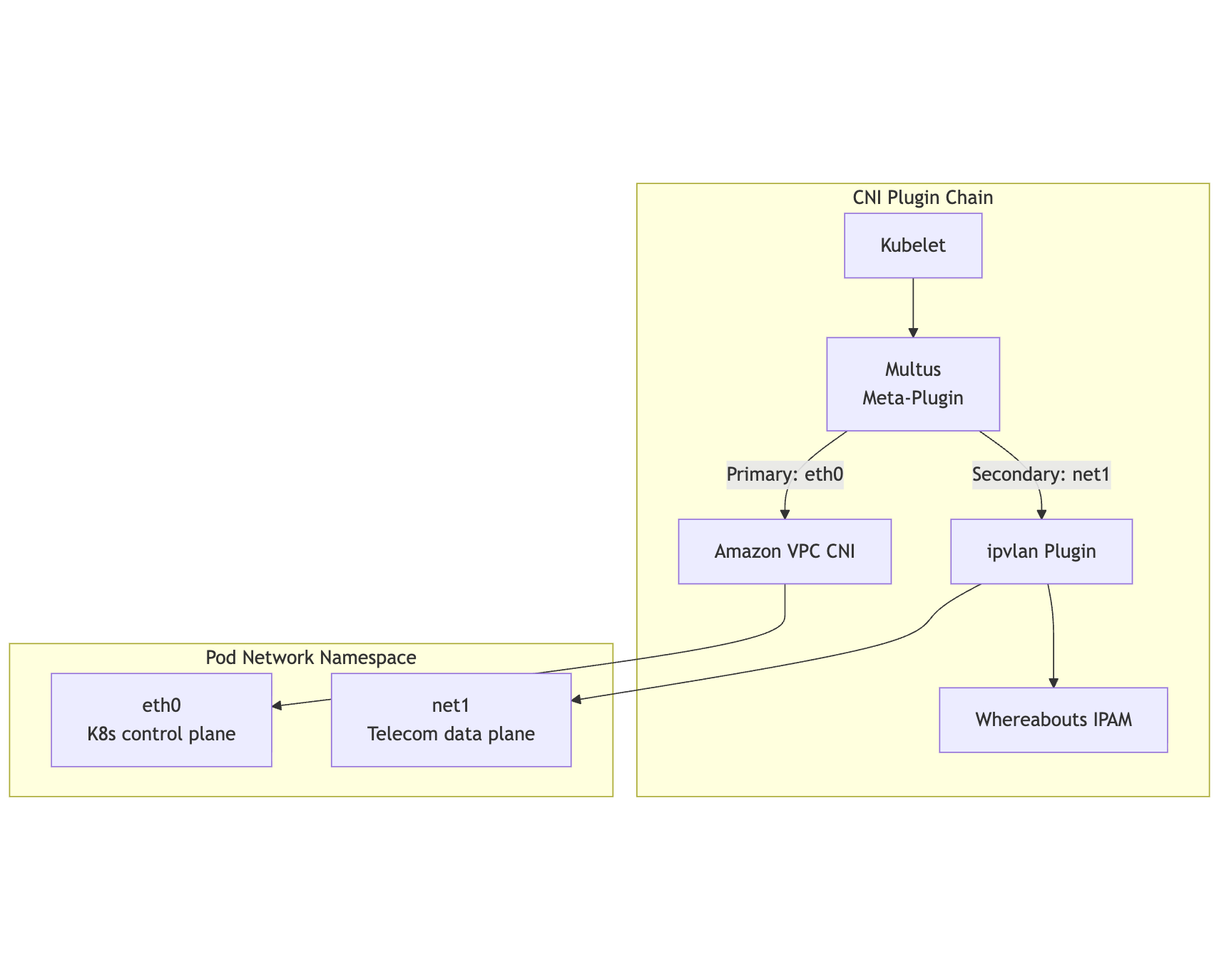
Multus Gave Me the Second Interface
Multus is a CNI meta-plugin. It does not replace the default pod network; it asks another CNI plugin to attach extra interfaces.
mermaid
flowchart TB
subgraph "CNI Plugin Chain"
Kubelet[Kubelet] --> Multus[Multus<br/>Meta-Plugin]
Multus -->|"Primary: eth0"| VPCCNI[Amazon VPC CNI]
Multus -->|"Secondary: net1"| IPVLAN[ipvlan Plugin]
IPVLAN --> Whereabouts[Whereabouts IPAM]
end
subgraph "Pod Network Namespace"
eth0_result[eth0<br/>K8s control plane]
net1_result[net1<br/>Telecom data plane]
end
VPCCNI --> eth0_result
IPVLAN --> net1_result
For the secondary interface I evaluated two practical modes:
| Mode | What it gives you | Cost |
|---|---|---|
ipvlan |
Multiple pod interfaces over the host ENI | Needs careful IPAM and routing |
host-device |
One physical or virtual device moved into the pod | Lower density; scheduling is harder |
ipvlan was the better default. It gave pod density and kept scheduling practical. host-device still makes sense when the network device itself is the unit of isolation, for example with SR-IOV-style setups.
The NetworkAttachmentDefinition is small, but every value matters:
apiVersion: "k8s.cni.cncf.io/v1"
kind: NetworkAttachmentDefinition
metadata:
name: telecom-net-az1
namespace: kube-system
spec:
config: |
{
"cniVersion": "0.3.1",
"type": "ipvlan",
"master": "eth1",
"mode": "l2",
"ipam": {
"type": "whereabouts",
"range": "10.0.2.128/26",
"gateway": "10.0.2.1"
}
}
And a pod opts in explicitly:
metadata:
annotations:
k8s.v1.cni.cncf.io/networks: telecom-net-az1
IPAM Was a Real Part of the Design
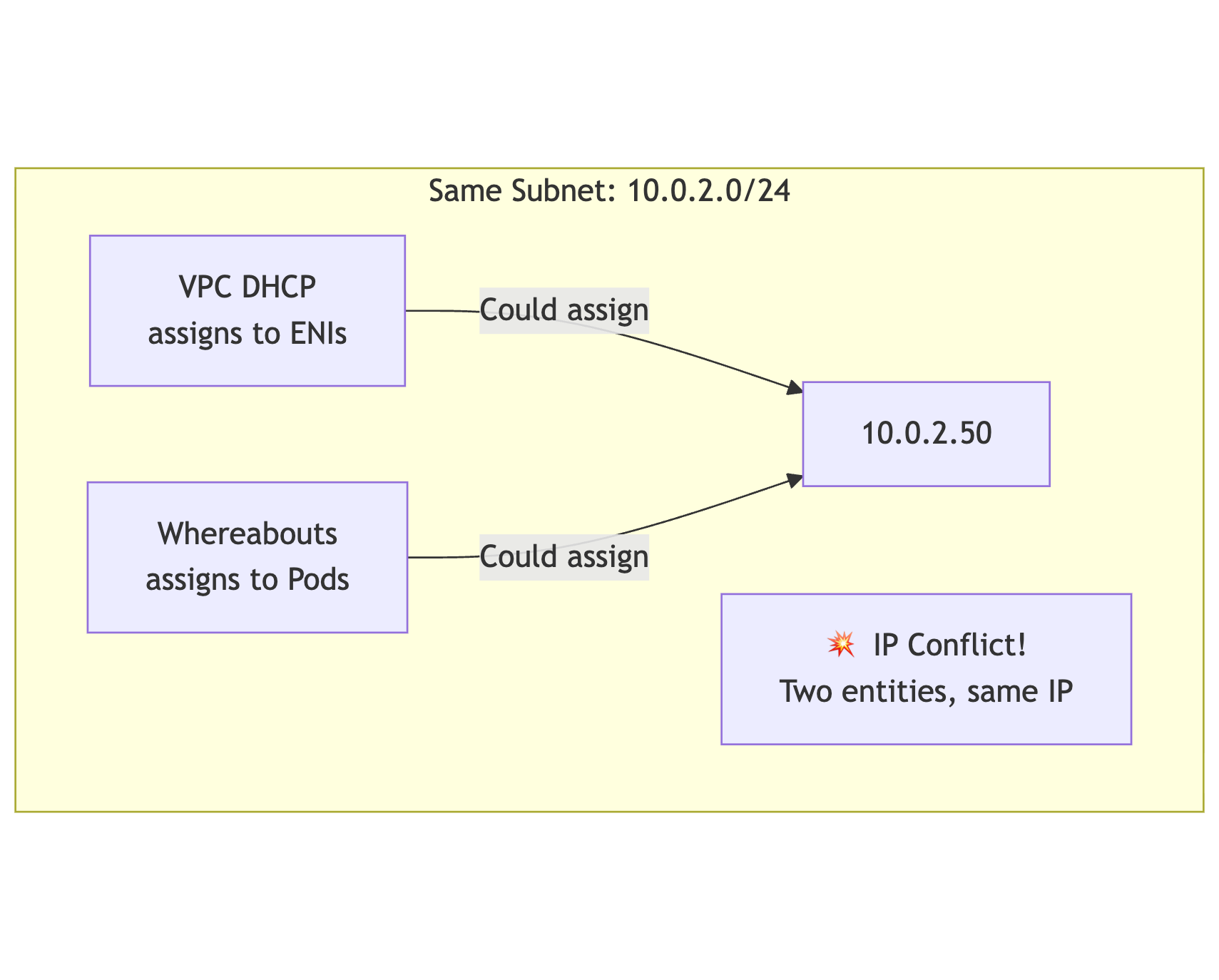
Whereabouts can assign an address to net1, but AWS VPC DHCP also assigns addresses from the subnet. If both systems believe they own the same range, sooner or later they can pick the same address.
mermaid
flowchart TB
subgraph "Same Subnet: 10.0.2.0/24"
DHCP[VPC DHCP<br/>assigns to ENIs]
WA[Whereabouts<br/>assigns to Pods]
DHCP -->|"Could assign"| IP1[10.0.2.50]
WA -->|"Could assign"| IP1
Conflict[💥 IP Conflict!<br/>Two entities, same IP]
end
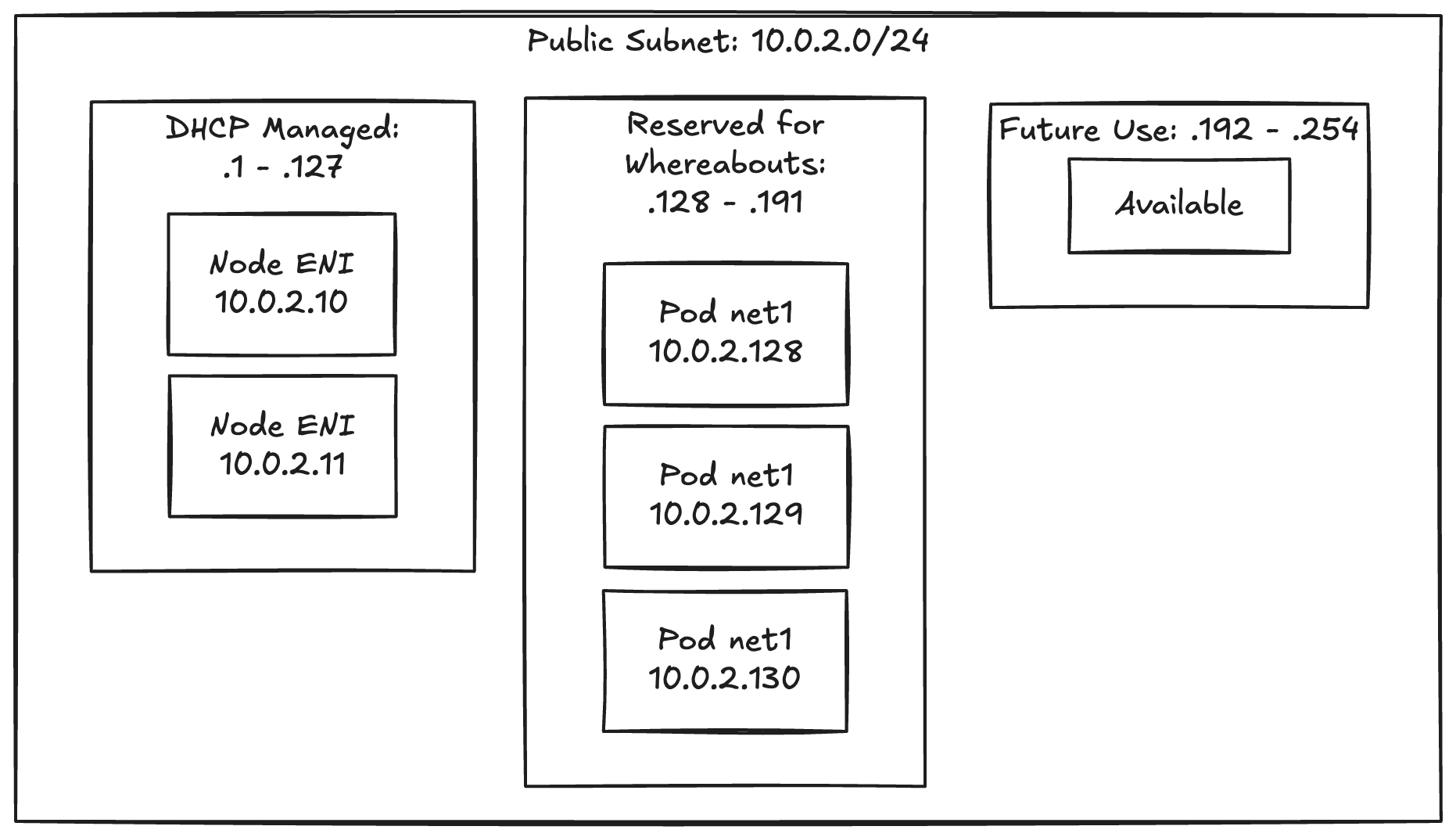
The fix was to reserve the pod range at the subnet level with a subnet CIDR reservation and make Whereabouts use exactly that range.
mermaid
flowchart LR
subgraph "Public Subnet: 10.0.2.0/24"
subgraph "DHCP Managed: .1 - .127"
ENI1[Node ENI<br/>10.0.2.10]
ENI2[Node ENI<br/>10.0.2.11]
end
subgraph "Reserved for Whereabouts: .128 - .191"
Pod1[Pod net1<br/>10.0.2.128]
Pod2[Pod net1<br/>10.0.2.129]
Pod3[Pod net1<br/>10.0.2.130]
end
subgraph "Future Use: .192 - .254"
Reserved[Available]
end
end
In Terraform, the important bit is the matching pair:
resource "aws_ec2_subnet_cidr_reservation" "whereabouts_az1" {
cidr_block = "10.0.2.128/26"
reservation_type = "explicit"
subnet_id = aws_subnet.public_az1.id
description = "Reserved for Multus/Whereabouts pod IPs"
}
ipam:
type: whereabouts
range: "10.0.2.128/26"
exclude:
- "10.0.2.128/30"
One easy trap: Whereabouts assigning 10.0.2.128 inside the pod is not enough. AWS must also know that this private IP belongs to the ENI before an Elastic IP can be associated with it; EC2 treats these as secondary private IPs on the network interface. In practice that means the controller or sidecar must reconcile both worlds:
- Observe the
net1address assigned by Whereabouts. - Ensure the private IP is registered on the right ENI.
- Only then associate the Elastic IP with that private IP.
If step 2 is missing, the design looks right from inside Linux and wrong from the VPC control plane.
An Elastic IP Is Only Half the Path
AWS Elastic IPs are a 1:1 NAT mapping at the Internet Gateway. An EIP can be associated with a private IP on a network interface, and incoming Internet traffic to the public IP is translated to that ENI private IP.
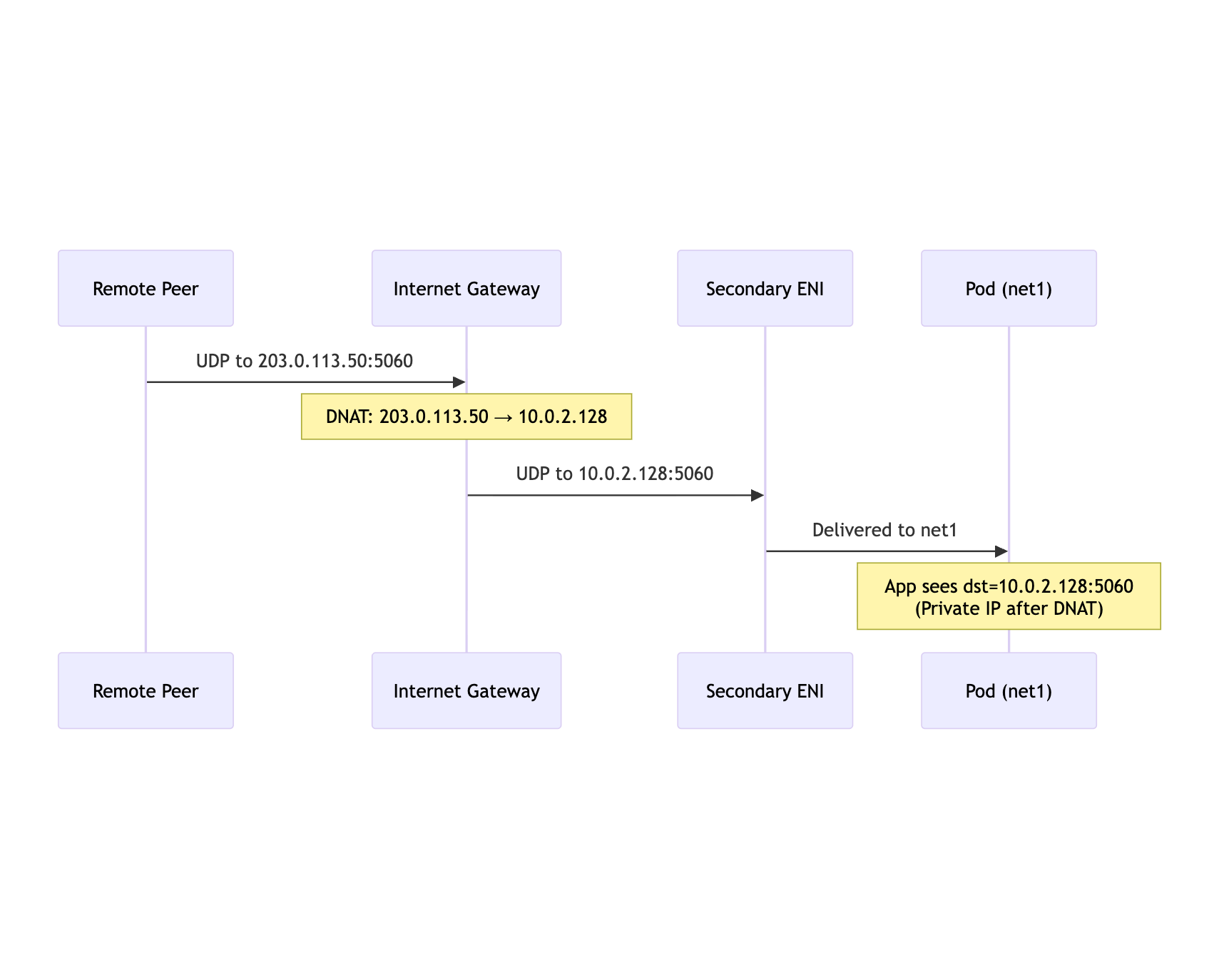
mermaid
sequenceDiagram
participant Peer as Remote Peer
participant IGW as Internet Gateway
participant ENI as Secondary ENI
participant Pod as Pod (net1)
Peer->>IGW: UDP to 203.0.113.50:5060
Note over IGW: DNAT: 203.0.113.50 → 10.0.2.128
IGW->>ENI: UDP to 10.0.2.128:5060
ENI->>Pod: Delivered to net1
Note over Pod: App sees dst=10.0.2.128:5060<br/>(Private IP after DNAT)
The return packet has to leave through the same public path. If Linux sends it through eth0, the packet is either dropped or exits through a path that does not match the advertised address.
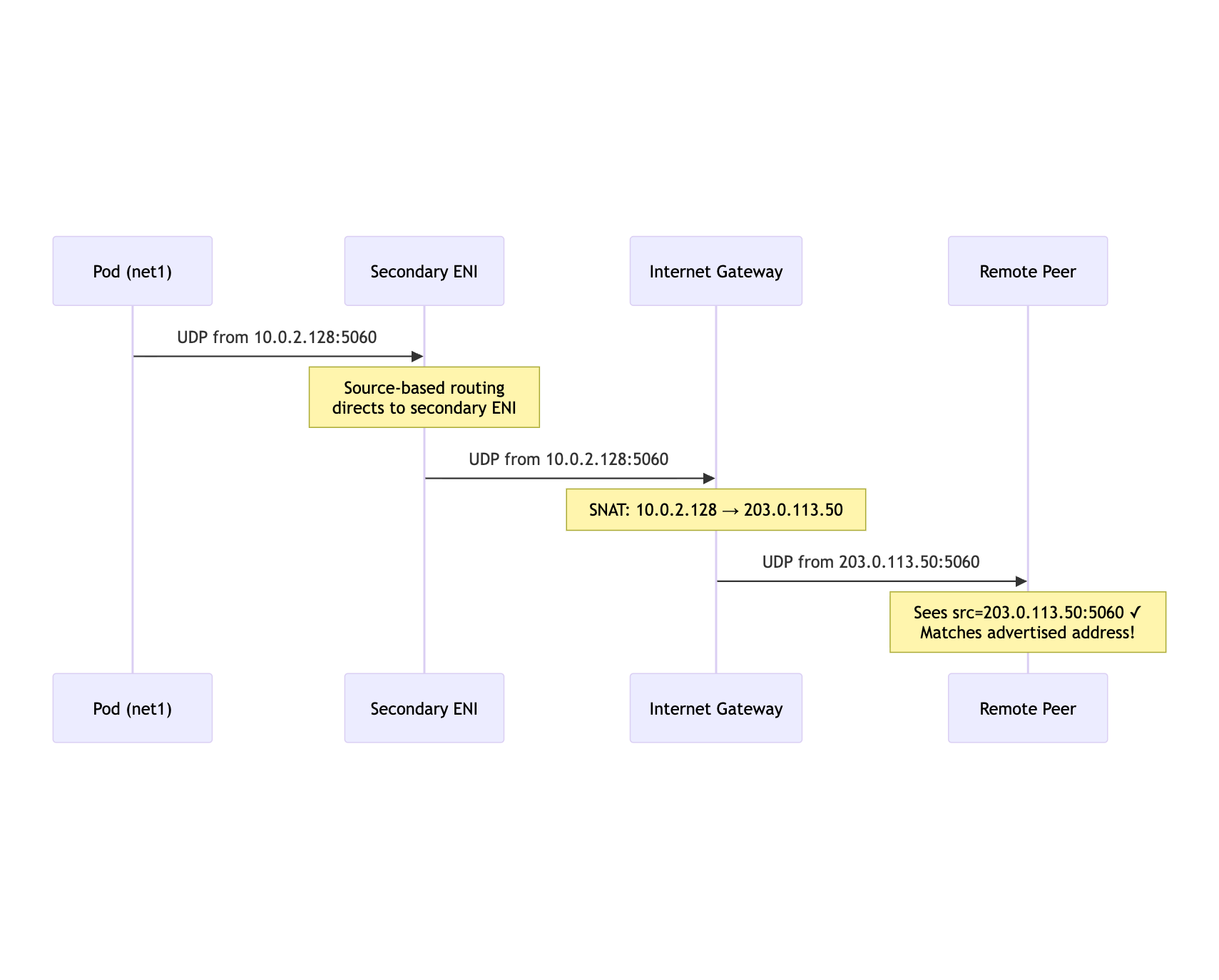
mermaid
sequenceDiagram
participant Pod as Pod (net1)
participant ENI as Secondary ENI
participant IGW as Internet Gateway
participant Peer as Remote Peer
Pod->>ENI: UDP from 10.0.2.128:5060
Note over ENI: Source-based routing<br/>directs to secondary ENI
ENI->>IGW: UDP from 10.0.2.128:5060
Note over IGW: SNAT: 10.0.2.128 → 203.0.113.50
IGW->>Peer: UDP from 203.0.113.50:5060
Note over Peer: Sees src=203.0.113.50:5060 ✓<br/>Matches advertised address!
The sidecar/controller logic is therefore not "allocate an EIP" and stop. It has to reconcile address ownership, association, routing, and cleanup.
I prefer to describe that logic like this:
func reconcilePublicIdentity(ctx context.Context, pod Pod) error {
privateIP := ipv4Address("net1")
eniID := ensurePrivateIPOnSecondaryENI(ctx, privateIP)
publicIP := claimElasticIP(ctx, "telecom-pool")
associateElasticIP(ctx, publicIP, eniID, privateIP)
replaceVPCRoutes(ctx, publicIP+"/32", eniID)
addLocalAddress("net1", publicIP+"/32")
addPolicyRoute("from "+privateIP+"/32", "telecom")
addPolicyRoute("from "+publicIP+"/32", "telecom")
writeFile("/shared/public-ip", publicIP)
return nil
}
That is deliberately incomplete. A real implementation needs idempotency, retries, tag-based ownership, stale route cleanup, race handling, and a safe answer for "what if the pod dies before cleanup runs?"
Replies Must Leave Through net1
Linux chooses routes primarily by destination. A packet received on net1 does not automatically reply through net1.
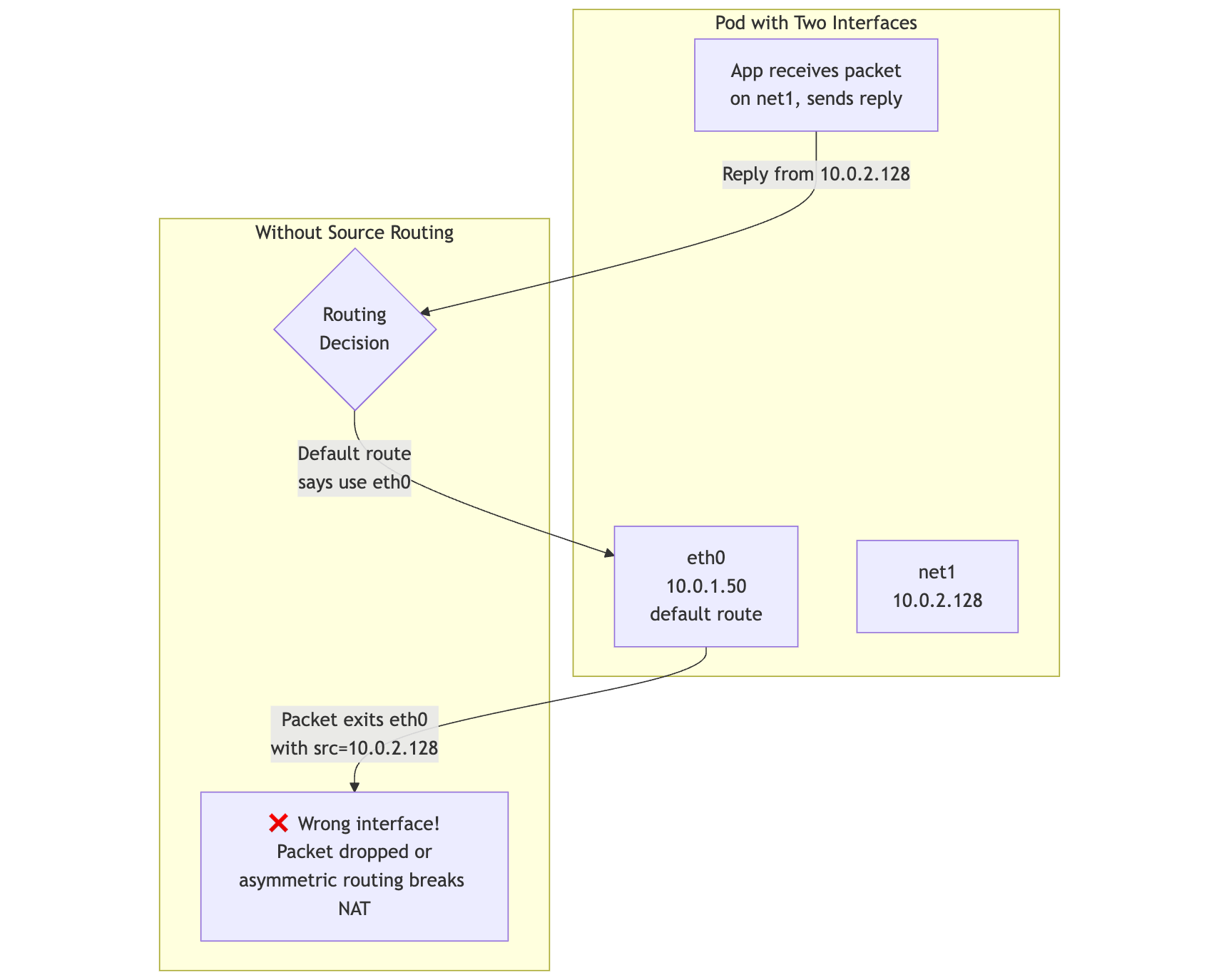
mermaid
flowchart TB
subgraph "Pod with Two Interfaces"
App[App receives packet<br/>on net1, sends reply]
eth0[eth0<br/>10.0.1.50<br/>default route]
net1[net1<br/>10.0.2.128]
end
subgraph "Without Source Routing"
App -->|"Reply from 10.0.2.128"| Decision{Routing<br/>Decision}
Decision -->|"Default route<br/>says use eth0"| eth0
eth0 -->|"Packet exits eth0<br/>with src=10.0.2.128"| Wrong[❌ Wrong interface!<br/>Packet dropped or<br/>asymmetric routing breaks NAT]
end
Policy routing is the correction:
echo "200 telecom" >> /etc/iproute2/rt_tables
ip route add 10.0.2.0/24 dev net1 src 10.0.2.128 table telecom
ip route add default via 10.0.2.1 dev net1 table telecom
ip rule add from 10.0.2.128/32 table telecom priority 100
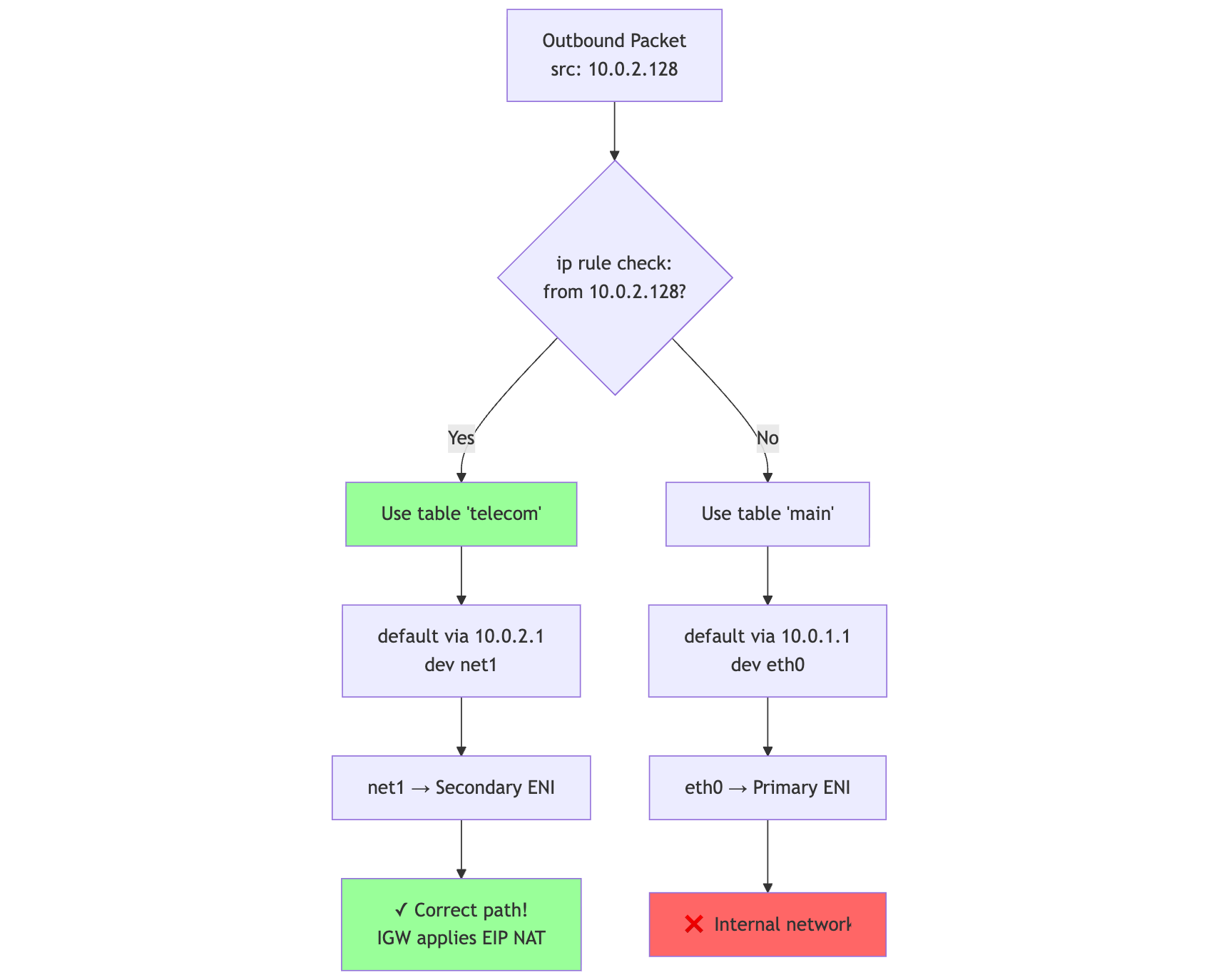
mermaid
flowchart TB
Packet[Outbound Packet<br/>src: 10.0.2.128]
Rule1{ip rule check:<br/>from 10.0.2.128?}
Packet --> Rule1
Rule1 -->|"Yes"| Table200[Use table 'telecom']
Rule1 -->|"No"| MainTable[Use table 'main']
Table200 --> Route200[default via 10.0.2.1<br/>dev net1]
Route200 --> net1_out[net1 → Secondary ENI]
net1_out --> Correct[✓ Correct path!<br/>IGW applies EIP NAT]
MainTable --> RouteMain[default via 10.0.1.1<br/>dev eth0]
RouteMain --> eth0_out[eth0 → Primary ENI]
eth0_out --> Wrong[❌ Internal network]
style Table200 fill:#9f9
style Correct fill:#9f9
style Wrong fill:#f66
Reverse path filtering is another quiet failure mode. Strict rp_filter can drop packets in setups where the kernel's best return path does not match the ingress interface during startup or failover.
sysctl -w net.ipv4.conf.all.rp_filter=2
sysctl -w net.ipv4.conf.net1.rp_filter=2
And on the secondary ENI, source/destination checks have to be disabled:
aws ec2 modify-network-interface-attribute \
--network-interface-id eni-xxx \
--no-source-dest-check
The rule I ended up using was this:
The pod may have two interfaces, but the advertised media identity gets exactly one return path.
The tcpdump Detail I Did Not Expect
After the public path worked, the next surprise came from internal traffic.
Internet-originated traffic to an EIP is DNATed by the Internet Gateway. By the time it reaches the pod, the destination is the private IP:
tcpdump -i net1 udp port 5060
# 198.51.100.50.5060 > 10.0.2.128.5060: UDP
# private IP after IGW DNAT
But VPC-internal traffic sent through a /32 route to the public IP can arrive with the public IP still as the destination:
tcpdump -i net1 udp port 5060
# 10.0.1.100.5060 > 203.0.113.50.5060: UDP
# public IP, no IGW DNAT
Without an explicit VPC route, the internal path is not reliable:
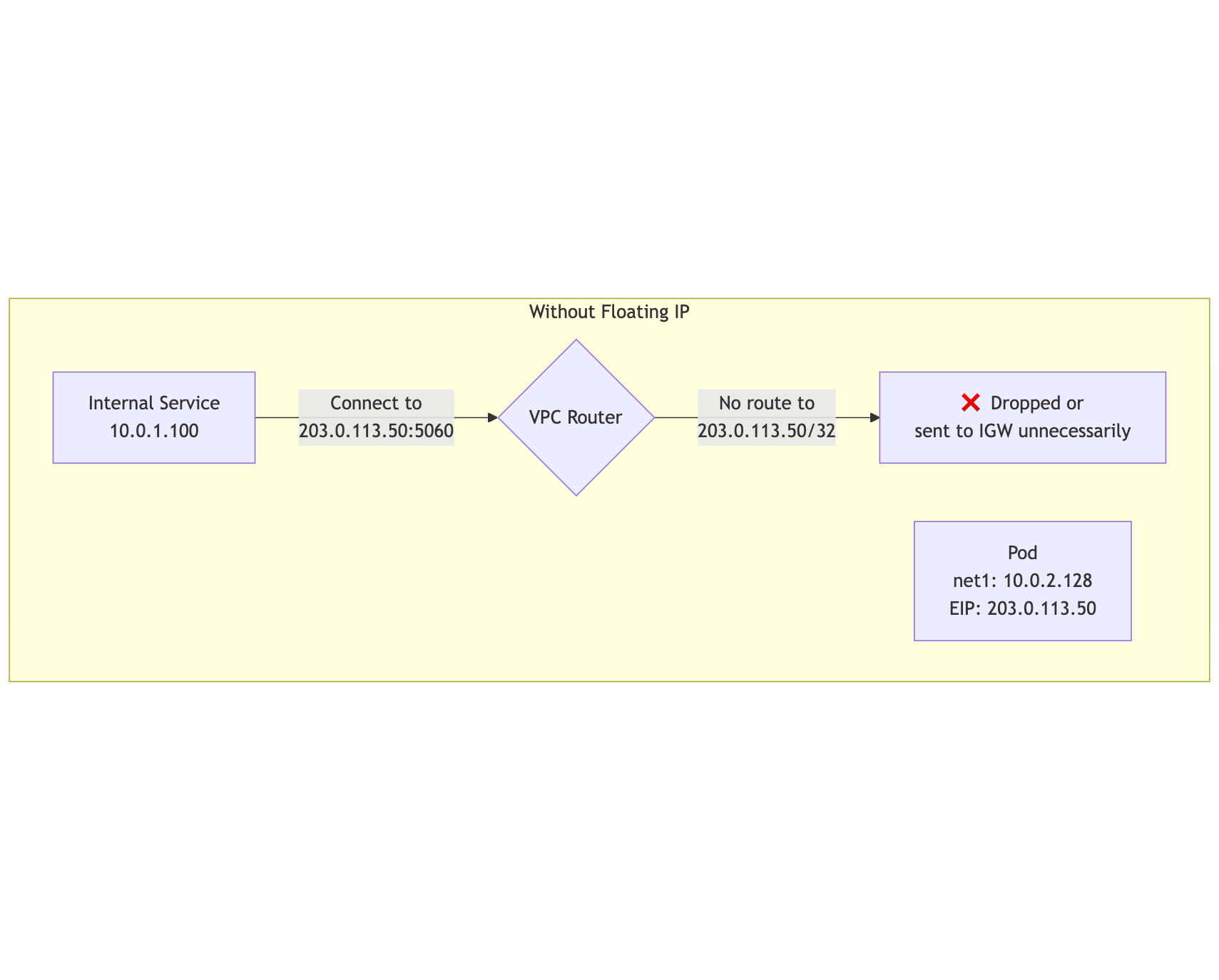
mermaid
flowchart TB
subgraph "Without Floating IP"
InternalClient[Internal Service<br/>10.0.1.100]
Pod[Pod<br/>net1: 10.0.2.128<br/>EIP: 203.0.113.50]
InternalClient -->|"Connect to<br/>203.0.113.50:5060"| VPCRouter{VPC Router}
VPCRouter -->|"No route to<br/>203.0.113.50/32"| Dropped[❌ Dropped or<br/>sent to IGW unnecessarily]
end
With a floating /32 route, the VPC can deliver traffic directly to the ENI:
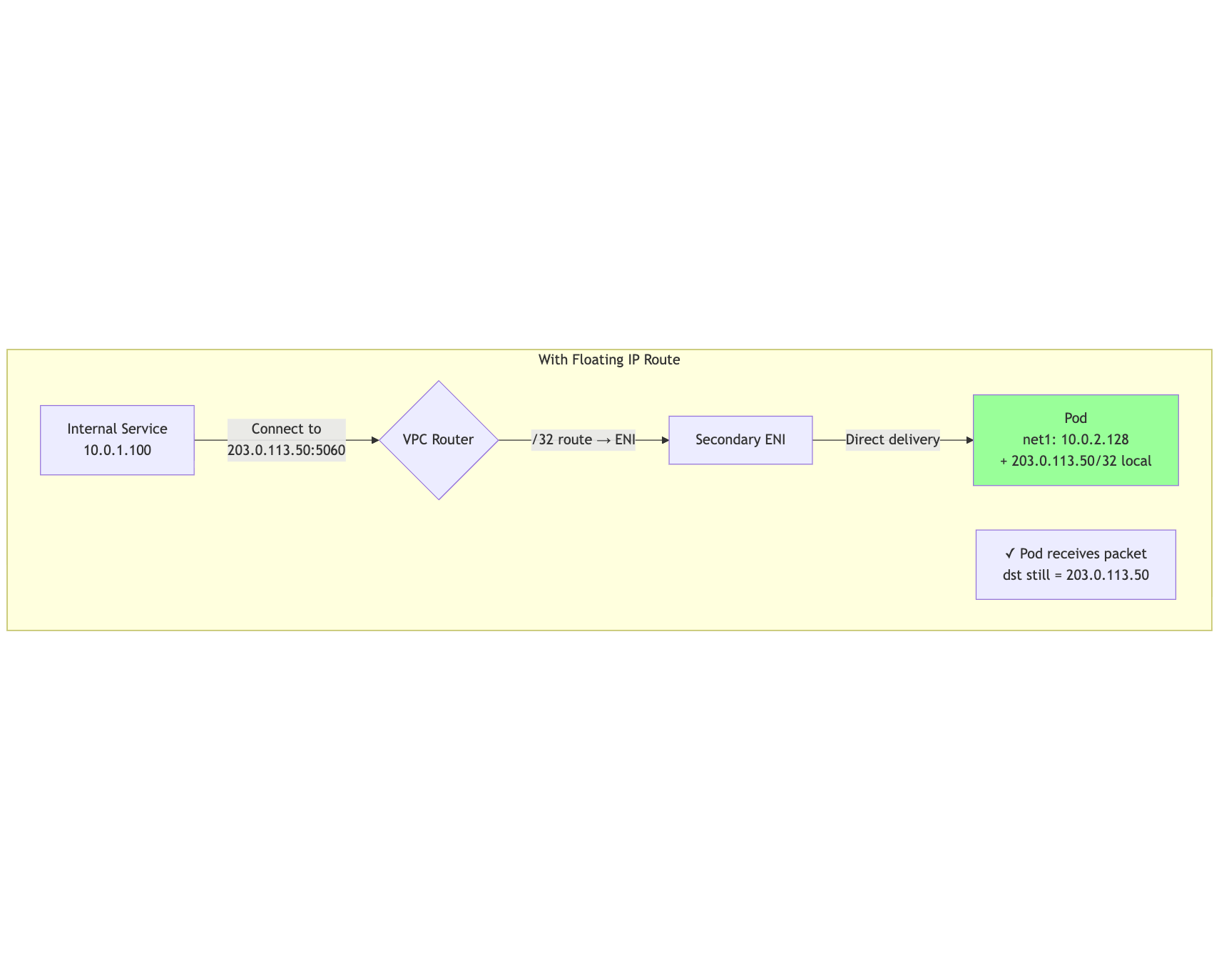
mermaid
flowchart TB
subgraph "With Floating IP Route"
InternalClient[Internal Service<br/>10.0.1.100]
Pod[Pod<br/>net1: 10.0.2.128<br/>+ 203.0.113.50/32 local]
InternalClient -->|"Connect to<br/>203.0.113.50:5060"| VPCRouter{VPC Router}
VPCRouter -->|"/32 route → ENI"| ENI[Secondary ENI]
ENI -->|"Direct delivery"| Pod
Note[✓ Pod receives packet<br/>dst still = 203.0.113.50]
end
style Pod fill:#9f9
That leaves an application decision:
| Option | Behavior | Tradeoff |
|---|---|---|
Bind 0.0.0.0 |
Accept either destination address | Simple, broad listener |
| Bind both IPs | Explicit sockets for private and public IPs | More application logic |
| Local DNAT | Normalize public destination to private IP | More iptables state |
For a service that only expects traffic on net1, local DNAT can be acceptable:
iptables -t nat -A PREROUTING -i net1 \
-d 203.0.113.50 -j DNAT --to-destination 10.0.2.128
The main point is to notice the difference. Otherwise you debug the wrong layer.
Lifecycle Is Part of the Design
Creating routes and EIP associations at pod startup means cleanup has to be a first-class path, not a best-effort shell trap.
Kubernetes native sidecars help because a restartable init container can start before the main container and terminate after it. That makes it a reasonable place to hold the public identity for the lifetime of the pod.
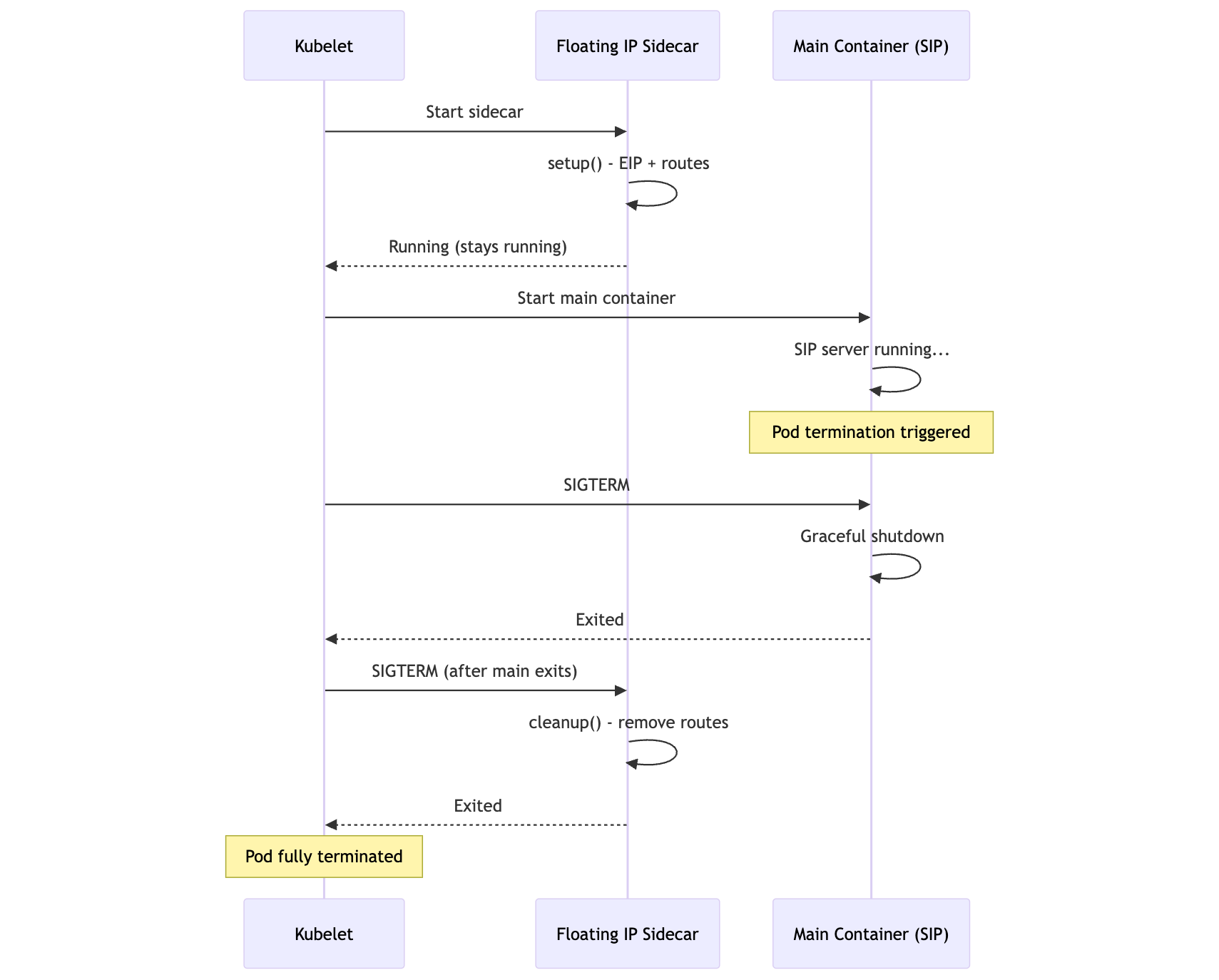
mermaid
sequenceDiagram
participant K as Kubelet
participant S as Floating IP Sidecar
participant M as Main Container (SIP)
K->>S: Start sidecar
S->>S: setup() - EIP + routes
S-->>K: Running (stays running)
K->>M: Start main container
M->>M: SIP server running...
Note over M: Pod termination triggered
K->>M: SIGTERM
M->>M: Graceful shutdown
M-->>K: Exited
K->>S: SIGTERM (after main exits)
S->>S: cleanup() - remove routes
S-->>K: Exited
Note over K: Pod fully terminated
Version detail matters here. Native sidecars were introduced behind a feature gate before becoming a stable API. On current Kubernetes, the pattern is:
spec:
initContainers:
- name: floating-ip-manager
image: my-registry/floating-ip-manager:latest
restartPolicy: Always
securityContext:
capabilities:
add: ["NET_ADMIN"]
I would still not rely only on pod shutdown. Node termination, forced deletion, control-plane interruptions, and cloud API timeouts can all leave stale routes or associated EIPs. A separate reconciler should be able to find resources by tag and clean up anything whose owning pod no longer exists.
The IAM policy should also be scoped as far as the implementation allows. A tutorial often shows Resource: "*", but the real policy should use tag conditions and only the route tables, ENIs, and EIPs this controller is allowed to manage.
Node Bootstrap Still Matters
The secondary ENI has to be attached, ignored by the VPC CNI, and ready before Multus starts scheduling workloads that depend on it.
The node-level work was roughly:
# Discover instance identity using IMDSv2.
TOKEN="$(curl -s -X PUT http://169.254.169.254/latest/api/token \
-H 'X-aws-ec2-metadata-token-ttl-seconds: 21600')"
INSTANCE_ID="$(curl -s -H "X-aws-ec2-metadata-token: $TOKEN" \
http://169.254.169.254/latest/meta-data/instance-id)"
REGION="$(curl -s -H "X-aws-ec2-metadata-token: $TOKEN" \
http://169.254.169.254/latest/meta-data/placement/region)"
# Find the secondary ENI attached for the media path.
SECONDARY_ENI="$(aws ec2 describe-network-interfaces \
--region "$REGION" \
--filters "Name=attachment.instance-id,Values=$INSTANCE_ID" \
"Name=tag:Purpose,Values=multus-telecom" \
--query 'NetworkInterfaces[0].NetworkInterfaceId' \
--output text)"
aws ec2 modify-network-interface-attribute \
--region "$REGION" \
--network-interface-id "$SECONDARY_ENI" \
--no-source-dest-check
aws ec2 create-tags \
--region "$REGION" \
--resources "$SECONDARY_ENI" \
--tags Key=node.k8s.amazonaws.com/no_manage,Value=true
I also prefer to taint these nodes until the Multus config is present. Otherwise a pod can land on a node that looks schedulable but cannot attach net1 yet.
taints:
- key: multus-not-ready
effect: NoSchedule
A tiny untainter DaemonSet can remove the taint after /etc/cni/net.d/00-multus.conf exists. The exact mechanism is less important than the invariant: do not schedule media pods before the second network path exists.
What I Would Validate Before Trusting It
I would not call this design working until these checks pass on a fresh pod:
ip addr show net1
ip rule
ip route show table telecom
ip route get 198.51.100.50 from 10.0.2.128
From AWS:
aws ec2 describe-network-interfaces \
--filters "Name=addresses.private-ip-address,Values=10.0.2.128"
aws ec2 describe-addresses \
--filters "Name=public-ip,Values=203.0.113.50"
aws ec2 describe-route-tables \
--filters "Name=route.destination-cidr-block,Values=203.0.113.50/32"
From the wire:
tcpdump -ni net1 udp port 5060
conntrack -L -p udp | grep 5060
And after deletion:
kubectl delete pod sip-server
# Then verify:
# - the EIP is disassociated or returned to the expected pool
# - /32 routes are gone or point to the new owner
# - no stale private IP remains assigned to the ENI
If cleanup only works in the happy path, it is not cleanup. It is a demo.
What This Design Commits You To
This design gives a pod a stable public media identity without moving the whole workload back to bare EC2. It also makes network identity part of workload lifecycle.
The useful properties are:
- SIP/RTP can advertise an address that matches the packet path.
- Multiple workloads can run in the same cluster without sharing a node IP.
- Kubernetes still owns rollout, placement, and normal service operations.
- Media traffic is separated from normal pod traffic.
The constraints are now explicit:
- Capacity is bounded by EIPs, public IPv4 cost, subnet reservations, and ENI private IP quota before CPU or memory may become relevant.
- The controller needs cloud API permissions, careful tagging, and ownership checks.
- Stale routes, EIP associations, and secondary private IP assignments need reconciliation.
- Public UDP exposure needs security groups, monitoring, and abuse handling.
- Multi-AZ placement must match the selected NAD, subnet, ENI, and route tables.
For SIP/RTP workloads that need stable public tuples, this is the Kubernetes design that matched the protocol constraint instead of hiding it behind another translation layer.
References
- Amazon EKS Multus Support
- EKS Multus Installation Guide
- Amazon EKS Multus User Guide
- Automated IP Management for Multus Pods
- Whereabouts IPAM
- Floating Virtual IP on EKS
- GCP Multus with ipvlan
- ICE: RFC 8445
- STUN: RFC 8489
- TURN: RFC 8656
- SIP: RFC 3261
- SIP rport: RFC 3581
- SIP Outbound: RFC 5626
- ICE SDP usage: RFC 8839
- Trickle ICE for SIP: RFC 8840
- Kubernetes Sidecar Containers
- AWS Subnet CIDR Reservations
- AWS EC2 Secondary Private IPs
- AWS EC2 AssociateAddress
- AWS Network Load Balancer routing
- AWS Network Load Balancer idle timeout
- AWS Network Load Balancer quotas